Renderer-based agent
Converts natural scene instructions into layout, camera trajectory, lighting, and renderable scene structure.
CVPR 2026
Lighting-grounded Video Generation with Renderer-based Agent Reasoning
LiVER turns a coarse 3D scene, camera trajectory, and HDR lighting into physically grounded render passes, then injects these cues into a video diffusion model for controllable photorealistic generation.
Peking University · BAAI · OpenBayes · Beijing University of Posts and Telecommunications
Diffusion models have achieved remarkable progress in video generation, but their controllability remains a major limitation. Key scene factors such as layout, lighting, and camera trajectory are often entangled or only weakly modeled, restricting their applicability in domains like filmmaking and virtual production where explicit scene control is essential. We present LiVER, a diffusion-based framework for scene-controllable video generation. To achieve this, we introduce a novel framework that conditions video synthesis on explicit 3D scene properties, supported by a new large-scale dataset with dense annotations of object layout, lighting, and camera parameters. Our method disentangles these properties by rendering control signals from a unified 3D representation. We propose a lightweight conditioning module and a progressive training strategy to integrate these signals into a foundational video diffusion model, ensuring stable convergence and high fidelity. Our framework enables a wide range of applications, including image-to-video and video-to-video synthesis where the underlying 3D scene is fully editable. To further enhance usability, we develop a scene agent that automatically translates high-level user instructions into the required 3D control signals. Experiments show that LiVER achieves state-of-the-art photorealism and temporal consistency while enabling precise, disentangled control over scene factors, setting a new standard for controllable video generation.
Method
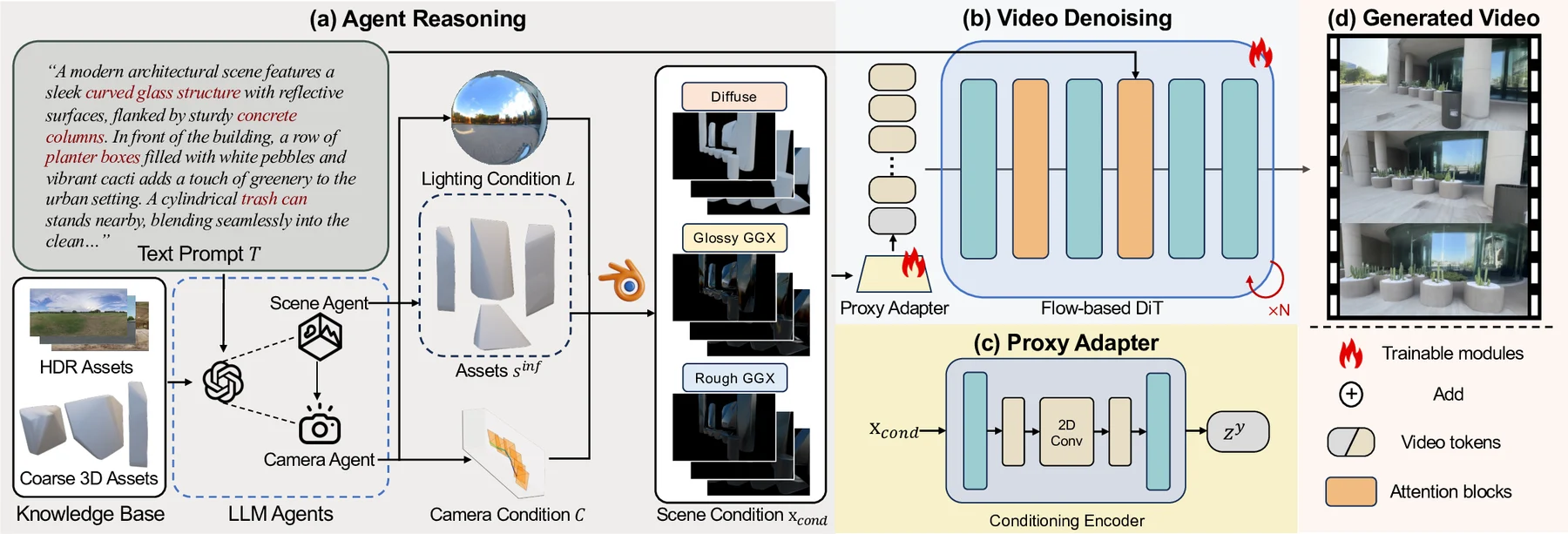
LiVER uses rendering as the contract between high-level scene intent and generative video synthesis. The agent prepares the scene; the renderer exposes physical cues; the diffusion model turns them into photorealistic frames.
Converts natural scene instructions into layout, camera trajectory, lighting, and renderable scene structure.
Uses diffuse, rough GGX, and glossy GGX passes to preserve physically meaningful illumination while staying compact.
Aligns renderer signals with a video foundation model while preserving temporal stability and visual fidelity.
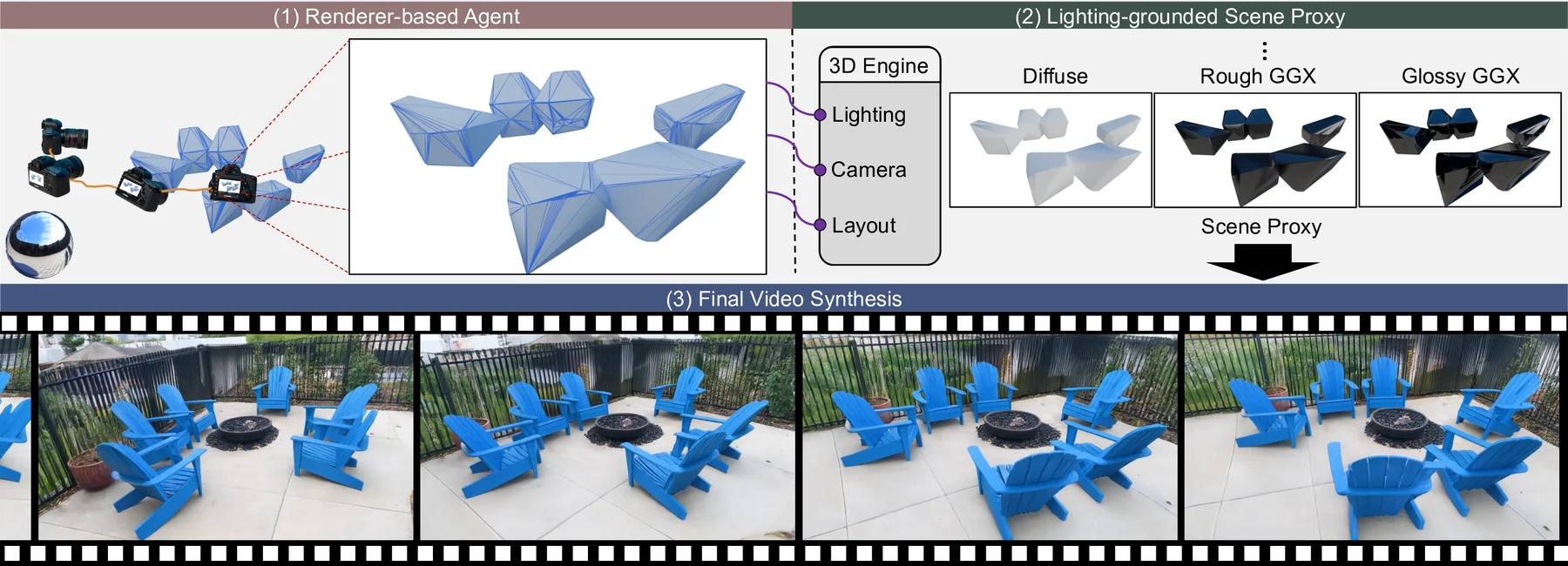
Pipeline
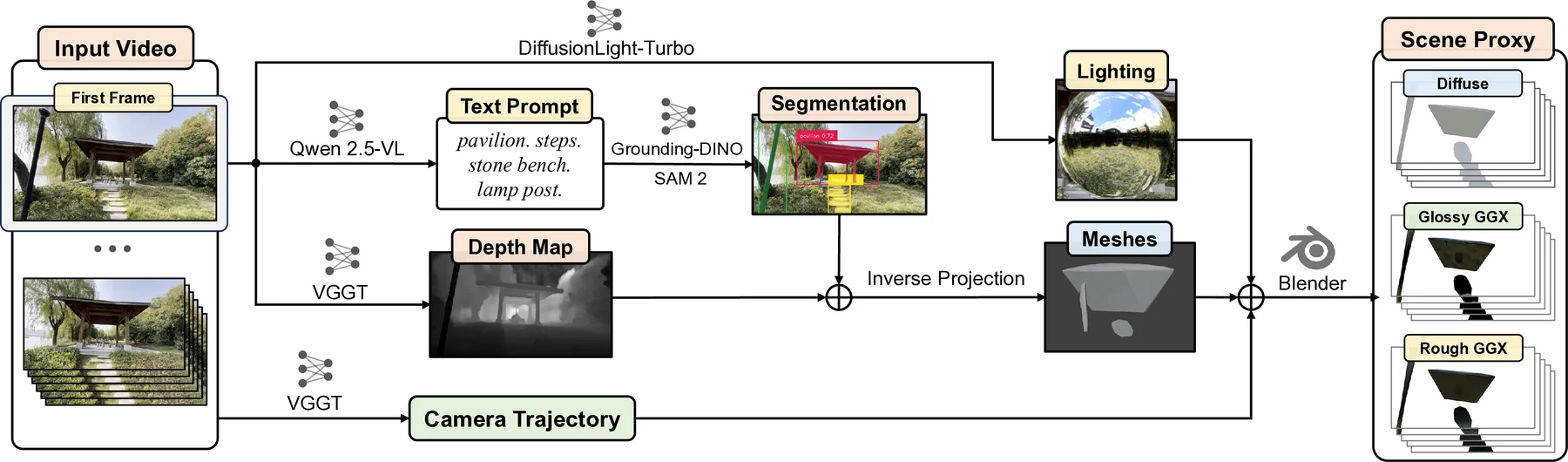
Scene Proxy




Control
Each pair keeps the scene content and viewpoint aligned while swapping the lighting condition, making the relighting effect explicit rather than mixing unrelated setups.
LiVERSet
LiVERSet combines real-world videos and synthetic physically based renders, with scene geometry, HDR environment maps, camera poses, and text descriptions.


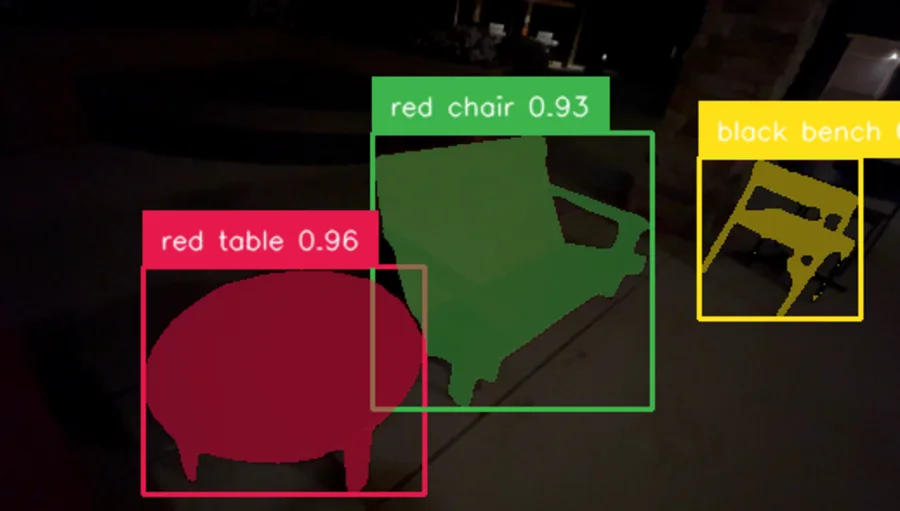

Results
Comparison
Citation
@inproceedings{cai2026liver,
title={Lighting-grounded Video Generation with Renderer-based Agent Reasoning},
author={Cai, Ziqi and Yang, Taoyu and Chang, Zheng and Li, Si and Jiang, Han and Weng, Shuchen and Shi, Boxin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}