ECCV 2026
Video Generation Models Are Inherent Lighting Estimators
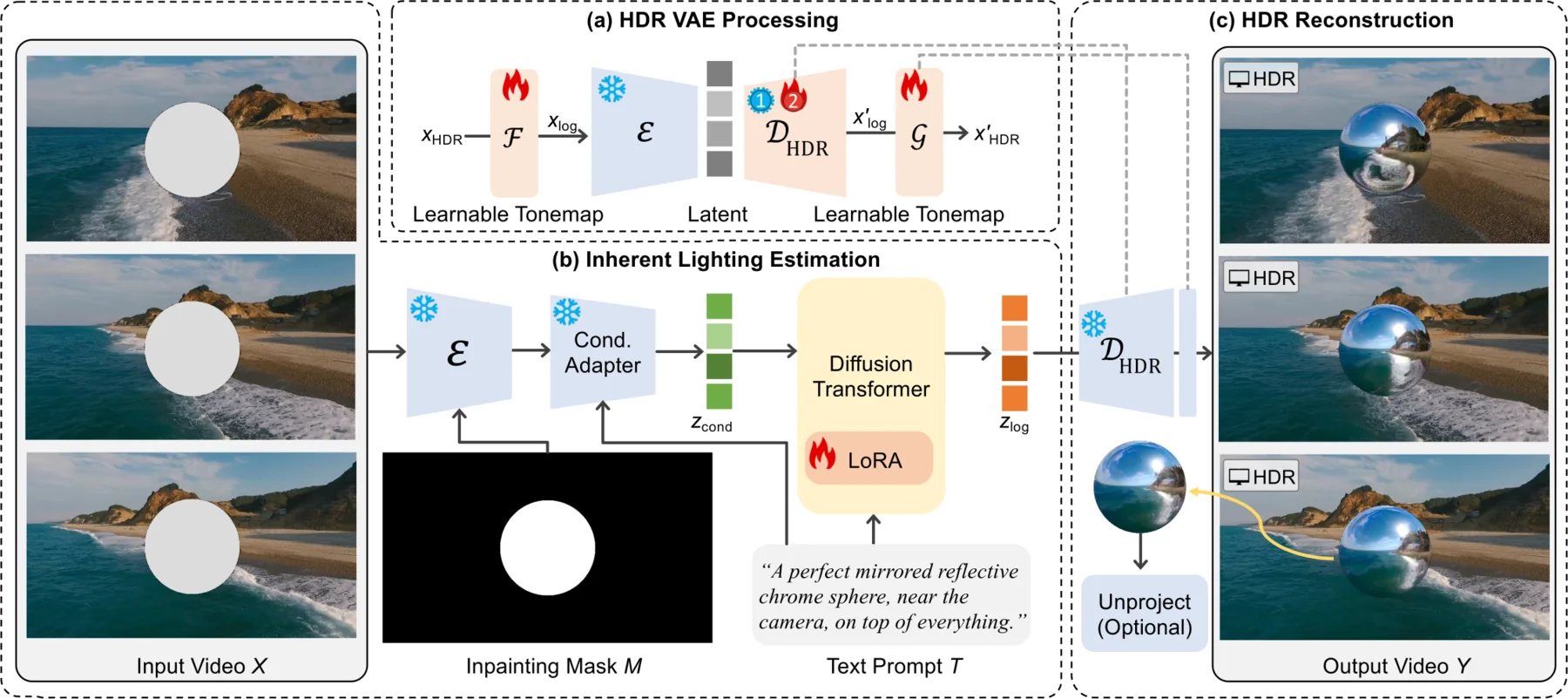
V-LITE reframes lighting estimation as guided video inpainting — insert a virtual chrome ball, and let a video diffusion model reveal the scene's dynamic HDR illumination.

 Background
+ Object · V-LITE
Background
+ Object · V-LITE